robots.txt und Crawler-SteuerungAlles zur robots.txt für die Suchmaschinenoptimierung
Die robots.txt ist ein mächtiges Werkzeug für Webmaster und Online Marketer, um Suchmaschinen zu steuern und von bestimmten Seiten auszuschließen. In diesem Wiki-Artikel gehen wir etwas tiefer auf die robots.txt ein: Was bedeutet die Datei, wie richte ich eine robots.txt ein und was hat sie für Auswirkungen auf Suchmaschinen?
Was ist die robots.txt?
Die robots.txt (ausgesprochen: "Robots Text") ist eine Datei im Hauptverzeichnis einer Website. Obwohl sie kein offizieller internationaler Standard ist (wie etwa HTML 5), hat sich die Datei und ihre Inhalte zu einem Faktisch-Standard entwickelt. Jedoch ist Google selbst daran, einen einheitlichen Standard für alle robots.txt-Dateien und für Bots und Crawler zu schaffen.
Der Sinn und Zweck einer robots.txt ist es, Crawler und Bots Anweisungen zu geben, wie sie sich auf einer Website und deren Unterseiten zu verhalten haben. Insbesondere der Ausschluss von Bots aus verschiedenen Verzeichnissen, Unterseiten und Dateien wird in der robots.txt geregelt. So werden beispielsweise Suchmaschinen wie Google oder Bing darauf hingewiesen, dass sie bestimmte Websites und andere Inhalte nicht besuchen dürfen oder sollen.
Wozu brauche ich eine robots.txt?
Wie bereits erwähnt ist die robots.txt ein wichtiges Mittel, um Suchmaschinen davon abzuhalten, bestimmte Inhalte aufzurufen. Somit blockieren wir Suchmaschinen wie Google beim Versuch, kritische Seiten aufzurufen. Dazu zählen:
- Administrative Verwaltung (Backend),
- Seiten mit Buchungsstrecken und Kaufvorgängen,
- temporäre Verzeichnisse und Dateien,
- Anmelde- und Kontaktformulare,
- Suchergebnisseiten
- sowie jede Art von Website oder Dateien, die wir explizit nicht im Index von Google und Co. sehen wollen.
Zugleich kann in der robots.txt eine XML-Sitemap hinterlegt werden. XML-Sitemaps sind Dateien, in denen man URLs an Suchmaschinen übermittelt, um etwa neue Seiten schneller in die Suchergebnisse zu bekommen. Gerade bei einem Website-Relaunch hilft die Anweisung, die neue Website schnell in die Suchergenisse zu bringen.
Was passiert ohne eine robots.txt Datei?
Ist keine robots.txt auf einer Website hinterlegt, gilt automatisch, dass alle Bots und Crawler alle Unterseiten und Dateien lesen und untersuchen dürfen. Bei einfachen und kleineren Webseiten ist das kein Problem, aber bei größeren Webseiten sollte man etwas genauer schauen, welche Inhalte denn auch mal nicht untersucht werden können.
Eine robots.txt einrichten
Die meisten Content Management Systeme verfügen selbst über einen automatisierten Mechanismus, der die robots.txt voll automatisch einrichtet. Üblicherweise steht darin, dass Suchmaschinen alle Seiten (bis auf Backend-Bereiche) untersuchen dürfen und hinterlegen gegebenfalls eine XML-Sitemap schon von selbst. In manchen Fällen wie WordPress passiert zweiteres (bezogen auf die XML Sitemap) über zusätzliche Plugins, wo wir das Yoast SEO Plugin empfehlen können. Unser hauseigenes CMS Condeon bringt für unsere Kundenwebseiten beides bereits mit.
Ist keine robots.txt vorhanden, kann man diese allerdings recht leicht hinterlegen.
- Schritt 1: Öffnen Sie einen Texteditor.
- TIPP: Wir empfehlen das Programm → Visual Studio Code, aber auch der normale Editor (Notepad) unter Windows funktioniert dafür prima.
- HINWEIS: Microsoft Word und andere Programme zum Erstellen von Dokumenten (etwa auch Open Office Writer) eignen sich nicht für die Erstellung einer robots.txt-Datei!
- Schritt 2: Fügen Sie entsprechende Befehle ein, auf die wir gleich unter → Tabelle: Befehle für die robots.txt eingehen
- Schritt 3: Speichern Sie die Datei unter dem Namen robots.txt ab.
- Schritt 4: Laden Sie die robots.txt ins Hauptverzeichnis Ihrer Website hoch.
- Beispielpfad für unsere Website: https://www.vioma.de/robots.txt
- HINWEIS: Die robots.txt wird in Unterordnern bzw. Verzeichnissen von Suchmaschinen nicht berücksichtigt. Das hochladen einer robots.txt-Datei macht hier keinen Sinn. Die robots.txt muss sich im Hauptverzeichnis der Website befinden.
Tabelle: Befehle für die robots.txt
Kommen wir nun zu den Befehlen, die wir in der robots.txt hinterlegen können. Sie ist nach einem gleichbleibenden Schema aufgebaut. Achten Sie deshalb auf den exakten Schreibstil (Groß- und Kleinschreibung) und darauf, dass pro Zeile ein Befehl hinterlegt werden darf. Unterhalb der Tabelle finden Sie Beispiele, wie eine robots.txt am Ende aussehen kann.
| Befehl | Beschreibung |
|---|---|
| # | Die Raute symbolisiert eine Notiz. Für Bots wie Googlebot bedeutet das, dass sie in dieser Zeile ab dem Rautezeichen alles ignorieren. So lassen sich eigene Notizen an die Befehle heften, um bei Änderungen schneller die passenden Stellen zu finden.Ist eine Raute am Anfang der Zeile hinterlegt, wird die gesamte Zeile ignoriert. Beispiel: # Dies ist eine Notiz. |
| * | Das Sternsymbol (bzw. Multiplikationszeichen) ist eine Wildcard. Wildcard bedeutet, dass sich anstelle des Sternsymbols irgendetwas an seiner Position befinden kann. Also ein beliebiger Teil der URL, oder wenn alle Bots angesprochen werden sollen. |
| User-agent: * | Beginnt eine Zeile mit User-agent: *, so bedeutet das, dass alle Bots ab dieser Zeile die darunter stehenden Befehle berücksichtigen sollen, bis ein neuer User-agent Befehl aufgelistet wird. Das Stern-Symbol (bzw. Multiplikationszeichen) stellt als Wildcard alle Bots dar, sodass alle Bots angesprochen werden. Beispiel: # Alle Bots und Crawler ansprechen |
| User-agent: Googlebot | Beginnnt eine Zeile mit User-agent: Googlebot, so wird nur der Google Bot angesprochen. Nur er soll die folgenden Zeilen berücksichtigen, bis ein neuer User-agent: aufgeführt wird. Andere Crawler und Bots berücksichtigen die darin befindlichen Befehle nicht. Anstelle von Googlebot kann man auch andere Bots gezielt befehligen. Beispiele: # Googlebot Eine Liste von Webcrawlern und Bots finden Sie hier: useragentstring.com |
| Disallow: / | Beginnt eine Zeile mit Disallow: bedeutet das, dass die zuvor angesprochenen Bots und Crawler einen dazu angefügten Pfad oder URL-Bereich nicht betreten dürfen. Es ist sozusagen ein Stopp-Schild für die jeweils angesprochenen Bots. HINWEIS: Ist keine Wildcard (Sternsymbol/Multiplikationszeichen) eingebaut, so gilt immer:
# Aussperren des gesamten Ordners und dieser Seite: |
| Disallow: /index.php$ | Das Dollarzeichen am Ende eines Pfades oder einer Datei sagt, dass die Berücksichtigung seitens der Bots bei dem Dollarzeichen endet. In diesem Fall wird die index.php im Hauptverzeichnis nicht berücksichtigt. Steht in der URL hinter index.php noch etwas – wie beispielsweise bei der URL /index.php?id=123 – dann berücksichtigen die Bots diese Seite wieder. Funktioniert nur mit Googlebot, Yahoo! Slurp, msnbot. Beispiel: # Aussperren einer URL, die mit index.php exakt endet: |
| Disallow: /temp/ | In diesem Fall ist es den jeweiligen Bots verboten, den Ordner /temp/ und alle darin befindlichen Dateien und Inhalte zu crawlen.Also: Ordnerstrukturen können von Zugriffen durch Suchmaschinen gesperrt werden. Beispiel: # Aussperren eines gesamten Verzeichnisses |
| Disallow: /admin.php | Sperrt für alle Bots und Crawler die Datei admin.php und alle Unterseiten, die die Seite generiert. Beispiel: # Aussperren der admin.php-Datei und möglichen Parameter-URLs |
| Disallow: /*.doc | Dieser Befehl sagt aus, dass es Bots und Crawler nicht gestattet ist, Dateien eines bestimmten Dateityps zu untersuchen. Weitere Beispiele: # Aussperren aus allen PDF-Dateien |
| Disallow: / Allow: /website/ |
Bots prüfen die robots.txt in der Regel von oben nach unten. Wurde vorher ein Bereich gesperrt (wie die komplette Website), aber weiter unten ist per Allow: ein Ordner freigegeben, so werden die Bots und Crawler den Ordner /website/ prüfen und in den Index aufnehmen. Funktioniert mit: Googlebot, Ask.com, Yahoo! Slurp, msnbot (andere Bots ignorieren möglicherweise die Reihenfolge!). Beispiel: # Aussperren von allen URLs, mit Ausnahme des /live/ Verzeichnisses |
| Sitemap: <URL> | In der robots.txt lässt sich auch die XML Sitemap hinterlegen. So wissen die Bots und Crawler gleich bescheid und werden die XML Sitemap überprüfen, um deren Inhalte schneller in den Index aufzunehmen. Beispiel: # Hinterlegen einer XML Sitemap: |
| Crawl-delay: <SEKUNDEN> | Speziell für Yahoo! und MSNbot: Deren Bots kann man anweisen, erst nach bestimmten Zeitabständen eine neue Seite zu crawlen. Beispiel: # Crawl Delay, in welchen Abständen MSNbot neue Seiten crawlen soll |
Beispiele einer robots.txt Datei
Zunächst der Inhalt und technische Aufbau einer robots.txt-Datei ohne Erklärungen und anschließend eine mit Erklärungen, die als Notizen markiert ist.
User-agent: *
Sitemap: https://www.vioma.de/google-sitemap.xml
Disallow: /temp/
#
User-agent: Googlebot
Disallow: /uploads/
Allow: /uploads/images/
#
User-agent: discobot
Disallow: /*list.
#
User-agent: msnbot
Disallow: /.js$
Und jetzt die gleiche robots.txt mit Notizen zur Erklärung. Die Notizen können ebenfalls in der robots.txt enthalten sein, da die Bots und Crawler die Notizen ignorieren.
# robots.txt für eine Website
#
# Die Raute # zu Beginn der Zeile
# sagt, dass es sich um einen
# Kommentar handelt und Bots
# diesen Bereich nicht
# berücksichtigen sollen.
#
User-agent: *
# alle Bots befolgen diese Anweisung,
# bis ein neuer User-agent genannt wird
#
Sitemap: https://www.vioma.de/google-sitemap.xml
# Hinterlegt die Sitemap für
# Crawler und Bots
#
Disallow: /temp/
# der Ordner /temp/ wird für alle
# Bots gesperrt
#
User-agent: Googlebot
# Ab hier ist nur der Googlebot betroffen
#
Disallow: /uploads/
# Googlebot darf nicht in den
# Ordner /uploads/
Allow: /uploads/images/
# Googlebot darf trotzdem in
# den Ordner /uploads/images/
#
User-agent: discobot
Disallow: /*list.
# Der discobot darf keine Dateien
# und Seiten öffnen, die list.
# in der URL beinhalten. Die
# Wildcard (*-Zeichen) sagt,
# dass es egal ist, was sich vor
# list. befindet.
#
User-agent: msnbot
Disallow: /.js$
# Der MSN Bot darf Javascripte
# nicht öffnen. Allerdings nur,
# wenn die Dateien mit .js enden.
# Befindet sich dahinter noch
# etwas, wie etwa bei
# skript.js?date=20191011, dann
# wird der MSN Bot die Datei
# durchsuchen.
# # ENDEWie reagieren Suchmaschinen auf gesperrte Inhalte?
Für Google und andere Suchmaschinen sowie jeden angesprochenen Bot und Crawler sind gesperrte Inhalte wie ein Stoppschild. Sie dürfen diese Seiten nicht besuchen und werden das in der Regel auch nicht tun. Somit werden Seiten, die per robots.txt gesperrt sind, nicht mehr von Googlebot und anderen Crawlern und Bots aufgerufen.
Allerdings ist die robots.txt eher als besonders wichtige Notiz für jede Art von Robot und Crawler zu verstehen. Während sich große Anbieter wie Google an die Verkehrsregeln (das sinnbildliche Stoppschild) halten, tun dies andere kleine Bots und Crawler nicht immer.
Außerdem ist das Sperren von Inhalten keine Garantie für die Nicht-Aufnahme in den Index von Suchmaschinen. Wird eine Seite von intern oder externen Quellen verlinkt, übernehmen Suchmaschinen gerne den Verlinkungstext als Suchergebnis-Überschrift. Da die Seiten aber nicht gecrawlt werden, irgnorieren Suchmaschinen Inhalte wie einen Noindex.
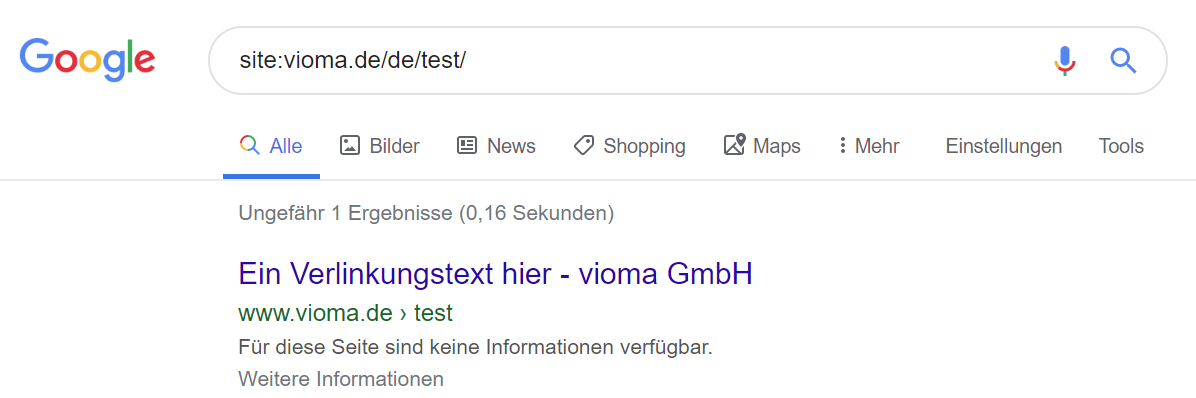 Beispiel eines Title Tags in den Google Suchergebnissen
Beispiel eines Title Tags in den Google SuchergebnissenTrotzdem, was das Untersuchen der Inhalte betrifft, halten sich die wichtigen und großen Suchmaschinen daran.
Hilft die robots.txt dabei, Duplicate Content zu vermeiden?
Von einem praktischen Standpunkt: Ja. Da Suchmaschinen die für sie gesperrten Inhalte via disallow-Angabe nicht untersuchen können, können sie auch keine Duplikate und somit kein Duplicate Content feststellen.
Wenn keine andere Möglichkeit gegen Duplicate Content vorzugehen besteht, kann man also die robots.txt wie folgt verwenden:
User-agent: *
Disallow: <URL Pfad nach der Domain, etwa:>
Disallow: /de/verzeichnis/mein-duplikat/
Stehen andere Möglichkeiten zur Verfügung, Duplicate Content zu vermeiden - etwa mit dem Zusammeführen und Weiterleiten von Seiten oder mittels Canonical Tag - sollten diese Varianten anstelle der robots.txt verwendet werden.
Was tun, wenn Inhalte bereits im Google Index sind?
Sind Seiten in den Google Index geraten, die man lieber nicht im Index haben möchte, sollte man die Dateien und Verzeichnisse nicht sofort per robots.txt aussperren. Denn der Ausschluss von Bots und Crawler bedeutet nicht, dass Suchmaschinen die Inhalte automatisch aus dem Index entfernen.
Besser ist dann folgende Vorgehensweise:
Ausschluss per Noindex & Entfernen per Google Search Console
- 1. Schritt: Die gewünschten Seiten auf Noindex setzen.
- 2. Schritt: Die gewünschten Seiten über die Google Search Console → URL prüfen → Indexierung beantragen
- Optionaler Schritt: Das gleiche über die Bing Webmastertools machen
- 3. Schritt: URLs in den Google Search Console entfernen lassen: Unter Vorherige Tools und Berichte → Entfernen
- 4. Schritt: Abwarten, bis die URLs tatsächlich entfernt wurden
- 5. Schritt: Die Pfade und Dateien per robots.txt erneut blockieren